

turning a Jane Street interview question blunder to a lesson

Friends,
Today we got ETFs, a volatility observation, and math.
Income ETFs
Off the back of my review of the ISBG and ISSB, Marcos from ETF Academy, invited me for a chat on income-based ETFs which are all the rage. People love yield. I got opinions. This one is a mix of spice and nutrition. Bon apetit.
Appreciating what high volatility means
SNDK is up ~40x in a year. The vol has justifiably exploded. If you want to bet on it halving by December (ie up 20x from where it was a year ago), the put spreads offer only about 2-1 odds.
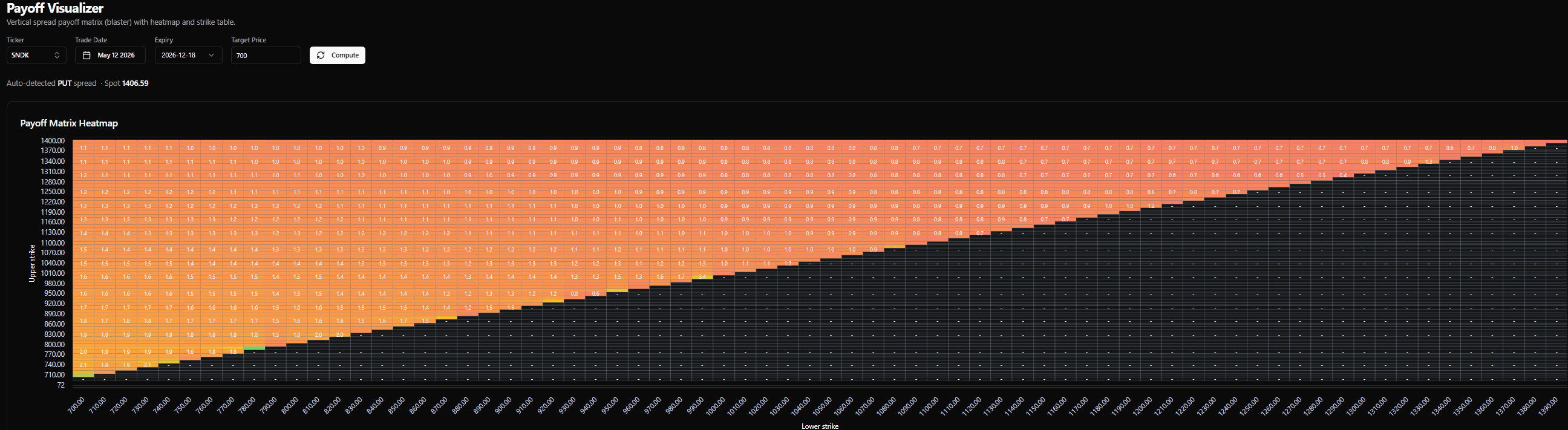
When you are 100 vol, getting cut in half is a 1 in 3 proposition.
The ricochet thought that should occur to you:
It is tough to make money in a reasonable risk-adjusted way once an asset is already high vol since it’s hard to size it without risking your neck. After all, it is well within the meat of the distribution for SNDK to get cut in half this year. That’s just a good baseball player’s chance of getting a hit or a typical NBA player hitting a 3 in a game (or missing a 3 in practice).
Math
If you ask Grok for threads about Jane Street interviews, a lot of people are sharing their war stories, but it’s also turned into a hilarious copypasta art form (example).
The genre led me to this game. It’s tongue-in-cheek but has real questions too.

I got an interview question wrong, which in itself isn’t bothersome, as they are designed to trip up smarter people than me. But the one I got wrong is in the realm of questions I should get right, which I do find compulsively bothersome.
I looked at the answer, but I know looking at answers doesn’t mean you necessarily learned. I wasn’t confident I could reproduce the answer or the answer to questions in a similar vein with twists.
So, I prompted Claude to teach me to answer it, but in a Socratic way. Then, for 2 days as I was drinking the morning coffee, I would rederive the identities and restate the meanings of the identities in words. Finally, do a couple of practice problems (like the dice version further below).
After 2 days, I felt like I got the idea, so I’ll continue on to a related topic, but I wanted to consolidate what I learned. I regurgitated my pen-and-paper effort to Claude to validate my work. Then, based on how I internalized this, I had Claude write an explainer emphasizing the points that I latched onto the most.
Between the process of generating the explainer and my editing of the post, this is a centaur (half-man, half-machine) article that helps you move frontwards and backwards between the concepts of simple multiplication, variance and expectation. A bonus of this approach is that you internalize volatility drag and Jensen’s Inequality by accident.
Variance Is Just A Difference Of Squares
There’s a piece of grade-school arithmetic everyone has done:
The difference of squares. You probably learned it as a parlor trick for multiplying numbers that sit symmetrically around a round number.
47 × 53?
That’s 50² − 9 = 2,491.
98 × 102? 100² − 4 = 9,996.
It turns out this same identity is the variance formula.
Once you see the connection, it makes one of the most important identities in probability feel obvious instead of memorized.
This post walks through the connection slowly, builds the variance identity from first principles, and ends with a clean drill set you can come back to.
The interview problem that started it
I flip a fair coin 100 times. What is the expected value of (number of heads) × (number of tails)?
The naive answer is 50 × 50 = 2,500. Heads and tails each average 50, so just multiply.
The naive answer is wrong. The right answer is 2,475. Off by 25.
Where does the 25 come from? It’s the variance of the number of heads. What is going on?
Setting up
Let H be the number of heads, T the number of tails. Every flip is one or the other, so:
H and T are not independent. They are perfectly negatively correlated.
Once you know H, T is fully determined.
So we can rewrite the product:
Take the expectation of both sides.
Expectation is linear, so it distributes over the subtraction and the constant 100 pulls out:
E[H] is easy. 100 fair flips, expected heads is 50. So 100 · E[H] = 5,000.
The interesting term is E[H²].
The trap: E[X²] is not (E[X])²
Squaring and averaging do not commute. Square first then average gives a different number than average first then square. Always.
Tiny example. X is either 0 or 100, each with probability ½.
E[X] = 50, so (E[X])² = 2,500
E[X²]: square the outcomes first (0 and 10,000), then average. That’s 5,000.
Different answers. 5,000 vs 2,500.
Squaring punishes deviations asymmetrically.
Going from 50 to 100 adds 50 to the input but adds 7,500 to the square. Going from 50 to 0 subtracts 50 from the input but only subtracts 2,500 from the square. The high side balloons faster than the low side shrinks. When you average the squared values, the ballooning wins.
This gap between E[X²] and (E[X])² has a name. It’s the variance.
In words: variance is the average of the squares minus the square of the average.
Where the formula comes from
The standard definition of variance is the average squared distance from the mean:
Expand the square:
Take the expectation of each term but keep in mind that μ = E[X] and μ is a constant, not a random variable. We computed it once and froze it. Constants pull out of E[·] freely.
Now substitute μ = E[X] everywhere it appears:
The two E[X]² terms collapse from −2 + 1 = −1. Done.
Two lessons from the derivation:
Whenever you see E, just think average. Probability-weighted, but average.
The mean is a number, not a random variable. Once you take E[X], the result is frozen.
Closing out the coin problem
Back to the interview question. We have:
Use the identity:
What’s Var(H)?
H is the sum of heads from 100 independent flips.
The variance of one flip is 0.25
Why?
2 equally likely outcomes of 0 and 1, so the mean is .5
deviations from the mean are .5, therefore the squared deviation is .25
Variances of independent flips add, so:
Therefore:
The answer falls short of the naive 2,500 by exactly Var(H)!
The product H · T peaks when H = 50 and pays a penalty whenever H drifts away from the mean (think of the extreme where H = 1, H · T = 99, meanwhile when H=50, H · T = 2500)
Averaged over the distribution of H, that penalty is exactly the variance. In investing contexts, that penalty on the expectation is volatility drag.
Numerical drills
Computing variances
Drill 1 — Two-outcome warmup
X is 0 or 10, each with probability ½.
E[X] = 5
(E[X])² = 25
E[X²] = average of 0 and 100 = 50
Var(X) = 50 − 25 = 25
Sanity check: deviations are ±5, squared deviations are both 25, average is 25. ✓
Drill 2 — Uniform on three values
X is uniform on {1, 2, 3}.
E[X] = 2
(E[X])² = 4
E[X²] = (1 + 4 + 9) / 3 = 14/3 ≈ 4.67
Var(X) = 14/3 − 4 = 2/3
Drill 3 — Asymmetric (lottery ticket)
X is 0 with probability 0.8, 10 with probability 0.2.
E[X] = 2
(E[X])² = 4
E[X²] = 0 · 0.8 + 100 · 0.2 = 20
Var(X) = 20 − 4 = 16
Standard deviation is 4 — bigger than the mean. Signature of a skewed payoff. Lottery tickets, insurance claims, venture returns all look like this.
Drill 4 — Single die roll
X is uniform on {1, 2, 3, 4, 5, 6}.
E[X] = 3.5
(E[X])² = 12.25
E[X²] = (1 + 4 + 9 + 16 + 25 + 36) / 6 = 91/6 ≈ 15.17
Var(X) ≈ 15.17 − 12.25 = 2.92
Computing E[X²]
Drill 5 — Going backwards
This is the direction you’ll actually use most often, because in practice you usually know the mean and variance of something and you need E[X²] to compute something else (a covariance, a portfolio variance, the second moment of a return distribution).
If E[X] = 6 and Var(X) = 9, then E[X²] = 36 + 9 = 45.
If E[X] = 0.10 and Var(X) = 0.04 (a stock with 10% expected return and 20% vol), then E[X²] = 0.01 + 0.04 = 0.05.
Drill 6 — Locked-together products
The original problem in disguise. X has E[X] = 10 and Var(X) = 4. Y = 20 − X.
20 · E[X] = 200
E[X²] = 100 + 4 = 104
E[X · Y] = 200 − 104 = 96
Naive answer (treating X and Y as independent): 10 × 10 = 100. Real answer is 96. Gap is 4, which is Var(X). Same pattern as the coin problem.
The connection to 43 × 37
We can link this to multiplication as I have shown before in how I explained vol drag to a 12-year-old.
Imagine a “random variable” with two outcomes: 43 with probability ½, and 37 with probability ½.
Mean: 40
Deviations from mean: +3 and −3
Squared deviations: 9 and 9
Variance: 9 (it’s the average of 9 and 9, which is just 9)
What’s the product of the two outcomes?
43 × 37 = 1,591.
And what does the difference-of-squares identity say it is?
The product equals mean² − variance.
Same shape as the coin problem, where the answer was 50² − 25 = 2,475.
[Note: The difference-of-squares identity gives you mean² − deviation². The variance identity gives you mean² − variance. They’re the same equation when your random variable has only two outcomes that are equidistant from the mean, because in that special case variance is the squared deviation. There’s only one squared deviation to average, so the average is itself.
For a more spread-out random variable like H (which can be 0, 1, 2, ..., 100), variance is still “average squared deviation from the mean” — it just averages over many outcomes instead of being a single squared distance.
The product of any two numbers is mean² − deviation²:
47 × 53 = 50² − 9 = 2,491
98 × 102 = 100² − 4 = 9,996
17 × 23 = 20² − 9 = 391
195 × 205 = 200² − 25 = 39,975
The grade-school arithmetic trick is a special case of variance.
Revisit Jensen
This explainer will make more sense now:
Jensen’s Inequality As An Intuition Tool
What to keep from this explainer
Three things, in order of importance.
E[X²] = (E[X])² + Var(X). Average of squares equals square of average plus the spread. E[X²] is always the bigger one. The gap is the variance.
Whenever you see E, think average. Probability-weighted average of whatever’s inside the brackets. Linearity makes E distribute over sums freely. Constants pull out. The mean of a random variable is itself just a number once you’ve computed it.
Locked-together products lose the variance. Anytime two things sum to a constant (H + T = 100, X + Y = 20), the expected product equals the product of the means minus the variance. The product peaks at the mean and pays a penalty for spread. That penalty, averaged over the distribution, is exactly Var.
A coda: covariance is just variance with two variables
There’s one more layer here, because it gives a clean name to the phenomenon driving the whole interview question.
We said the expected product H · T comes up short of the naive 2,500 by exactly Var(H) = 25. Why?
Because H and T move opposite to each other. When H is above its mean, T is below. They’re locked together by H + T = 100.
The quantity that measures this kind of co-movement is covariance:
The average of the product of deviations. Think about the sign of that product on a typical outcome:
X and Y both above their means → positive × positive = positive
X and Y both below their means → negative × negative = positive
X above, Y below (or vice versa) → positive × negative = negative
X and Y unrelated → product is sometimes positive, sometimes negative, averages to zero
So covariance is positive when they move together, negative when they move opposite, zero when they’re unrelated.
The computational identity
Apply the same FOIL-and-take-expectations trick we used for variance. Multiply out:
Take expectations term by term, remembering that μ_X and μ_Y are constants and pull out of E freely:
Substitute μ_X = E[X] and μ_Y = E[Y]:
Three copies of E[X]E[Y] with coefficients −1, −1, +1 collapse to a single −E[X]E[Y]:
Same shape as the variance identity:
Average of the product minus the product of the averages.
And if you set Y = X, this collapses back to Var(X). Covariance of a variable with itself is its variance:
Variance is the special case. Covariance is the bigger object.
Diagnosing the missing 25
Rearrange the covariance identity:
The naive answer to the interview question assumed Cov(H, T) = 0. Plugging in what we actually know:
So Cov(H, T) = −25.
The missing 25 was negative covariance.
That’s not just numerically equal to −Var(H). It is −Var(H), and it has to be, by the structure of the problem.
Why Cov(H, T) = −Var(H)
Let’s prove it directly.
We need one new property of covariance: it’s linear in each argument. Constants pull out, and sums split apart. Same as expectation.
Specifically:
Cov(X, A + B) = Cov(X, A) + Cov(X, B)
You can prove this in two lines from the identity we just derived (FOIL the product, use linearity of E).
We also need one tiny fact: covariance with a constant is zero.
Look at the definition. If Y is a constant c, then (Y − μ_Y) = 0 always, because a constant equals its own mean. Zero times anything is zero. Constants don’t co-vary with anything, because they don’t vary at all.
Now the calculation.
T = 100 − H. Treat that as a sum: the constant 100 plus the random variable −H.
Split the sum:
The first term is Cov of a random variable with the constant 100, which is zero. For the second term, pull the −1 out the same way you’d pull a constant out of expectation:
But Cov(H, H) = Var(H).
So:
There it is:
Whenever two variables sum to a constant, their covariance equals the negative of either’s variance!
The H + T = 100 constraint forces them to move one-for-one in opposite directions, which is the most negative covariance the structure can produce.
The whole problem in one sentence
The answer falls short of E[H] · E[T] by exactly Var(H), because Cov(H, T) = −Var(H) when H and T sum to a constant.
Stay groovy
☮️
love of the game ah post. 10/10. read 35% of it and realized I dont put this much effort into a problem ive annoyingly gotten wrong. 🫶🏼 u da toughest 🫶🏼